The Fall of Constantinople for Amazon's Mechanical Turks?
Using LLMs and ChatGPT in oTree experiments
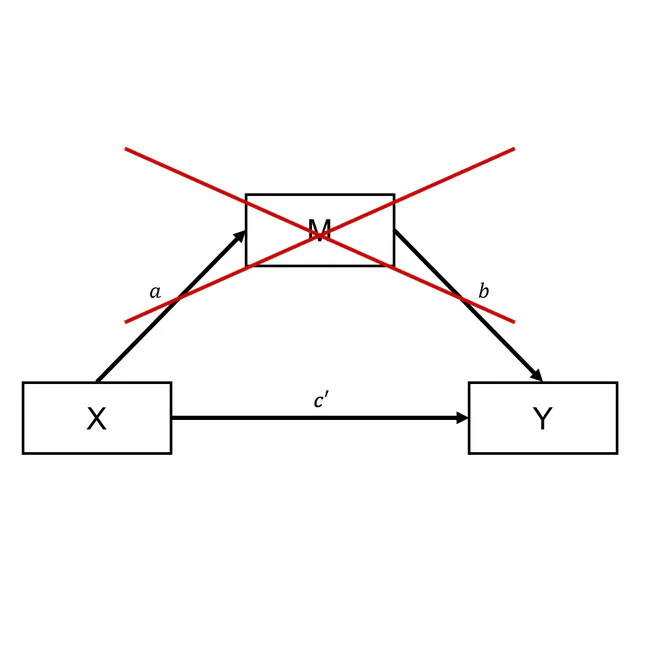
Why you shouldn't trust mediation as process evidence



Replications can help improve relevance of accounting experiments



The role of exploratory analyses in accounting research



Choosing the right participants

Why PEQs do not provide the best process evidence



Automize testing your experiments with 'bots'

What do participants think of accounting experiments?

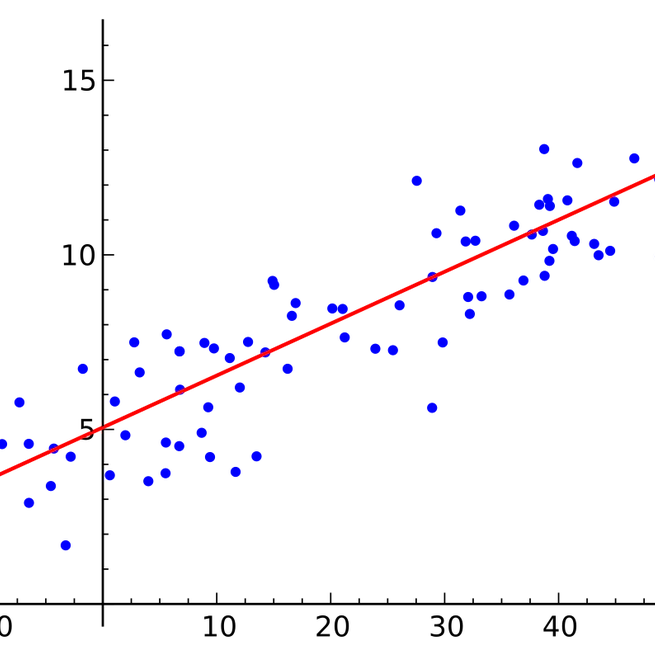

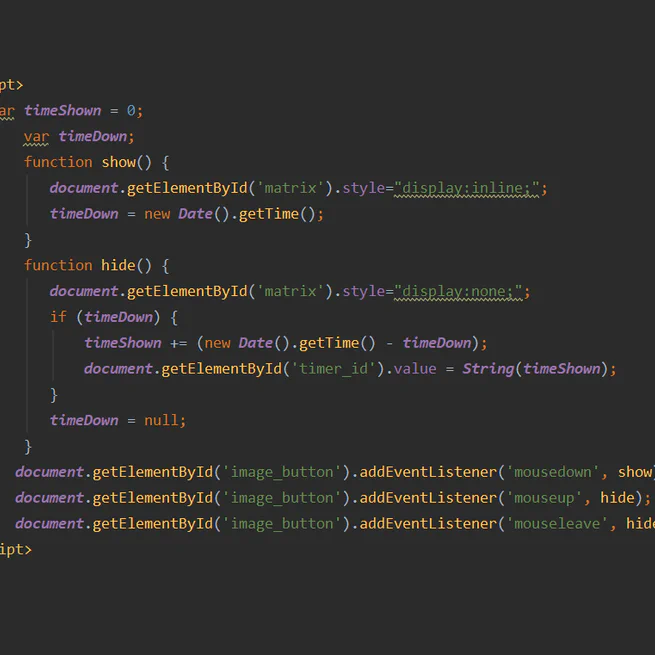

Deception when generating random numbers